
Abstract
자연의 이미지에서의 문자인식은 해결하지 못한 문제로써 해결해내야하는 과제이다.
문서와 달리 자연 이미지의 단어는 원근 왜곡, 곡선 문자 배치 등으로 인해 불규칙한 형태를 띄는 경우가 많다.
그래서 본논문은 불규칙한 텍스트에 강한 모델인, RARE를 제안한다.
RARE는 Spatial Transformer Network (STN)과 Sequence Recognition Network (SRN)를 포함하는 딥러닝 네트워크로 디자인되었다.
테스트에서 이미지는 먼저 예측된 Thin-Plate-Spline(TPS) 변환을 통해 먼저 수정되고, SRN을 통해서 더 읽기 쉬운 이미지가된다.
제안하는 모델을 통해서 원근적이거나 구부러진 텍스트를 포함하는 여러 형태의 불규칙한 텍스트를 인식할 수 있게 한다.
RARE는 이미지와 관련한 라벨링만을 필요로하여 end-to-end 학습이 가능하기때문에 실제적인 시스템에서 학습하고 적용시키는 것이 편리하다.
제안하는 모델을 통해서 여러 벤치마크에서 높은 성능을 선보였다.
Introduction
자연적인 장면에서 텍스트는 여러종류의 물체에서 나타난다. (ex, road signs, billboards, and product packaging)
이것은 이미지를 이해함에 있어서 높은 수준의 정보를 전달한다.
이미지에서 문자인식을 하는것은 지리 위치, 무인 자동차 및 이미지 기반 기계 번역과 같은 실제사용하는 많은 어플리케이션을 용이하게 한다.
이러한 이유들로, 장면 문자인식은 커뮤니티로부터 큰 관심을 끌었다.
OCR에 대한 어느정도 성장한 연구가 있음에도 불구하고, 스캔한 문서보다 자연이미지에서의 문자인식은 여전히 해결해야하는 문제이다.
장면 문자 인식은 조명에 따라 큰 변화를 보인다.(ex, motion blur, text font, color)
게다가 야생에서의 문자는 불규칙적인 형태를 가지고 있다.
예를 들어 몇몇의 scene text는 카메라 앵글로 인한 원근감이 있는 문자이며, 몇몇은 구부러진 형태이다. 이것은 그 특징들이 직선이 아닌 곡선을 따라 배치된다.
우리는 이런 텍스트를 불규칙한 텍스트라고 한다.
보통 문자인식기는 입력이미지가 촘촘히 짜여진 문자를 포함할때 좋은 성능을 낸다.
이것이 본논문에서 인식기가 더 잘 읽을 수 있게 입력 이미지를 바로 잡을 수 있게하기 위해 인식전에 spatial transformation을 적용하는 것에 동기부여가 됐다.
본논문에서는 불규칙한 문자에 강한 인식 기법을 제안한다.
Spatial Transformer Network(STN)과 Sequence Recognition Network(SRN)을 결합한 딥러닝 네트워크로 구성하였다.

STN를 통해 입력이미지는 공간적으로 변형되어 수정된 이미지가 된다.
이상적으로 STN은 SRN에 입력하기위한 더 적절한 규칙적인 텍스트를 만들어낸다.
그 변형은 TPS 변형으로, 비선형성을 통해 원근법 및 곡선 텍스트를 포함한 다양한 유형의 불규칙적인 텍스트를 수정할 수 있다.
TPS 변형은 좌표가 컨볼루션 신경망에 의해 회귀되는 일련의 기준점에 의해 구성된다.
규칙적인 문자를 포함하는 이미지에서 특징들은 수평의 라인으로 정렬되어 있다.
이것은 순차 신호와 어느 정도 유사하다.
이러한 점에서 동기부여를 받아서 SRN의 경우 시퀀스 인식 접근법에서 텍스트를 인식하는 attention-based 모델로 구성했다.
SRN은 encoder와 decoder로 구성된다.
입력이미지가 주어지면 encoder가 특징벡터들의 순서인 순차적인 특징 표현을 만들어낸다.
decoder는 주기적으로 각 단계에서 attention 메커니즘에 의해 결정되는 관련 내용을 디코딩하여 입력 시퀀스에 대한 문자 순서 조절을 만들어낸다.
본논문에서는 적절한 초기화를 통해서 전체모델이 end-to-end로 학습될 수 있음을 보여준다.
결과적으로 STN의 경우 어떠한 위치적인 정답값(TPS의 기준점의 위치)을 라벨링할필요는 없고, 역전파된 오류의 차이에 의해서 학습이 감독되게한다.
실제적으로 학습은 결국 STN이 SRN에 바람직한 입력인 규칙적은 텍스트를 포함하는 이미지를 만들어내는 경향이 있게만든다.
본논문의 contrbution은 세가지로 요약할 수 있다.
1. 불규칙한 텍스트에 강한 새로운 scene text recognition 방법을 제안한다.
2. RARE는 attention-based model과 함께 STN 프레임워크를 확장하였다. 원래의 STN은 일반적인 CNN에서만 테스트되었었다.
3. SRN의 encoder에 convolutional-recurrent structure를 적용하였다. attention-based model의 새로운 변형이다.
Proposed Model
전반적으로 모델은 입력이미지 Ⅰ를 가지고 시퀀스 l = (l1, . . . , lT )를 출력한다. (lt 는 t-th character, T는 변화하는 문자열 길이이다.)
1. Spatial Transformer Network
STN은 예측된 TPS 변형으로 입력이미지Ⅰ를 수정된 이미지 Ⅰ' 로 변형시킨다.

위 그림과 같이, 먼저 localization 네트워크를 통해 기준점들의 집합을 예측한다.
그 다음 grid generator 안에서 Fiducial Points로부터 TPS 변환 파라미터를 연산하고 입력이미지의 sampling grid를 생성한다.
Sampler는 grid와 입력이미지 두개를 가지며, grid points 샘플링에 의해 수정된 이미지Ⅰ' 를 만들어낸다.
STN의 차별적인 특성은 샘플러를 구별할 수 있다는것이다.
그러므로 구별할수있는 localization network와 grid generator를 가지면, STN은 오류의차이를 역전파시키고 학습시킬수 있다.
① Localization Network
localization network는 x,y 좌표를 직접적으로 회귀함으로써 K fiducial points의 위치를 알아낸다.
여기서의 상수 K는 짝수이다.
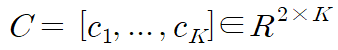 |
(1) |
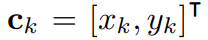 |
(2) |
좌표는 (1)과 같은 식으로 표기된다. k번째 열(2)는 k번째의 fiducial point의 좌표들을 포함한다.
xk, yk가 [-1, 1] 범위 내에 있도록 이미지 중심이 되는 정규화된 좌표계를 사용한다.
regression을 위해서 CNN을 사용한다.전통적인 구조들에 비슷하게 CNN은 convolution layer, pooling layer, fc-layer들을 포함한다.그러나 본논문에서는 regression을 classification을 대신해서 사용한다.마지막 fully-connected layer인 출력층을 위해 출력 노드의 수를 2K로 설정하고 활성화 함수를 tanh(·)로 설정하고 출력 벡터의 값이 (-1, 1) 범위 내에 있도록 한다.마지막으로 출력 벡터느 C로 재형성된다.
네트워크는 전반적인 이미지의 문맥들을 기반으로 fiducial points의 위치를 알아낸다.이것이 입력이미지의 전체적인 텍스트 형태를 캡쳐하는 것을 기대하며 이에따라 fiducial points의 위치를 알아낸다.어떠한 샘플에도 fiducial points의 좌표에대해 주석을 달지 않는것을 강조해야한다.대신, localization network의 학습은 역 전파 알고리즘에 따라 STN의 다른 부분에 의해 전파되는 gradients에 의해 완벽하게 감독된다.
② Grid Generator
grid generator는 TPS변형 파라미터들을 추정하고 sampling grid를 발생시킨다.
먼저 또다른 fiducial points의 집합을 정의하고 이것을 base fiducial points라고 부르며 $$C^{'} = [c _{1} ,...,c _{K} ] \in R ^{2 X K}$$으로 표기한다.

위 그림처럼, base fiducial points는 수정된 이미지의 상하단 가장자리를 따라 고르게 분포된다.
K가 상수이고 좌표계가 정규화되었으므로 C'은 항상 상수이다.
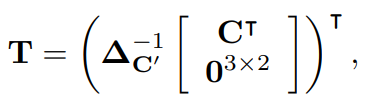 |
(3) |
 |
(4) |
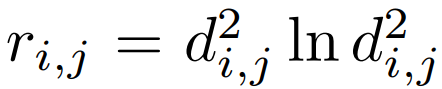 |
(5) |
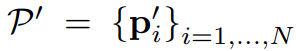 |
(6) |
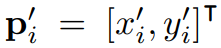 |
(7) |
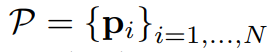 |
(8) |
TPS 변형의 파라미터는 $$T\in R^{2X(K+3)}$$의 행렬로 표현되며 (3)에 의해 연산되고 $$\bigtriangleup _{C'}$$은 (4)와 같은 행렬이며 이또한 상수이다.R의 i번째 행과 j번째 열에 있는 원소는 (5)이며, di,j는 c'i와 c'j 사이의 유클리디안 거리이다.
수정된 이미지의 grid의 픽셀은 (6)과 같이 표기되고, (7)은 i번째 픽셀의 x,y좌표이고, N은 픽셀의 수이다.수정된 이미지의 모든 (7)은 아래와 같은 변형을 적용해서 Pi와 상응하는 것을 찾았다.
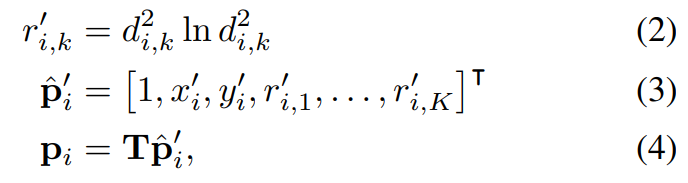
di,k는 (7)과 k번째 base fiducial point 사이의 유클리디안 거리이다.
(6)의 모든 포인트들의 반복함으로써 입력이미지에서 grid (8)을 만들어낸다.
grid generator는 그것의 두 행렬 곱셈은 둘 다 미분 가능하기 때문에 gradient들을 역전파할수있다.
③ Sampler
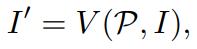 |
(9) |
마지막으로 Sampler에서 픽셀값(7)은 입력이미지의 근처 Pi로부터 양선형 보간된다.
모든 픽셀값들을 세팅함으로써 수정된 이미지 (9)를 얻는다.
(9)에서 V는 bilinear sampler를 의미하며, 미분가능한 모듈이다.

TPS 변형의 유연성은 불규칙한 텍스트 이미지들을 규칙적인 텍스트를 포함하는 수정된 이미지로 변형하게 한다.
위그림과같이 몇몇의 흔한 유형을 보여준다.
a)는 텍스트검출의 불완전함을 유발하는 늘어지게 쓰여진 텍스트이다.
b)는 수평적이지않은 카메라의 시선이 원인인 다중 지향 텍스트이다.
c)는 측면시선의 카메라 각도가 원인인 원근적인 텍스트이다.
d)는 예술적 스타일로 흔하게 보이는 구부러진 텍스트이다.
STN은 이러한 불규칙한 텍스트들을 포함하는 이미지를 recognizer가 더 잘 읽을 수 있게 수정할수 있게한다.
2. Sequence Recognition Network
목표가 되는 단어들은 본질적으로 글자들의 순서이기 때문에, 인식의 문제를 순서의 인식문제로써 모델링하고 순서 인식 네트워크로 다룬다.
SRN에 입력되는 수정된 이미지는 이상적으로 왼쪽에서부터 오른쪽으로 수평적으로 쓰여진 단어를 포함한다.
수정된 이미지로부터 순차적인 표현을 추출하고 그것으로 부터 단어를 인식한다.
본논문의 모델에서 SRN은 attention-based model로 입력이미지로부터 순서를 직접적으로 인식한다.
SRN은 encoder와 decoder로 구성된다.
encoder는 수정된 이미지로부터 순차적인 표현을 추출한다.
decoder는 주기적으로 각 단계에서 관련된 내용을 디코딩하여 순차적 표현에 의해 조건화된 순서를 발생시킨다.
① Encoder: Convolutional-Recurrent Network
수정된 이미지에 대한 순차적 표현을 추출하기 위한 순진한 접근법은 왼쪽부터 오른쪽까지 지역적인 이미지 패치들을 받아서 CNN으로 그들 각각을 묘사하는 것이다.
그러나 이러한 접근법은 겹치는 패치들 사이에서 연산을 공유하지 않아 비효율적이다.
게다가 패치들간의 공간 의존성은 이용되거나 영향을 주지않는다.
대신에 convolutional layers와 순환 네트워크를 결합하는 네트워크를 설계한다.
이 네트워크는 순서의 특징벡터들을 추출한다. 임의의 크기의 입력 이미지가 주어진다.

위그림과 같이, encoder의 하단은 여러개의 convolutional layer가 있다.
convolutional layer들은 입력이미지에 대해서 강렬하고 높은 수준의 묘사를 하는 특징을 만든다.
feature maps이 &&D_{conv} X H_{conv} X W_{conv}&&의 크기를 가지고 있다고 가정할때, D는 깊이, H는 높이, W는 너비이다.
다음 수행은 maps를 일련의 W 벡터로 변경하는 것이다.
특별히 map-to-sequence 수행은 맵의 열을 왼쪽에서 오른쪽 순서로 꺼내 벡터로 평탄하게 만든다.
CNN의 변형 불변성에 따르면, 각 벡터는 receptive field와 같고, 그 지역을 설명해준다.
receptive field의 크기에 의해 제한되는 특징 시퀀스는 제한되는 이미지 문맥들을 활용한다.시퀀스의 장기적 의존성을 모델링하기 위해 두개의 레이어인 BLSTM 네트워크를 시퀀스에 적용한다.
BLSTM은 양방향의 시퀀스 내의 의존성을 분석할 수 있는 순환 네트워크로, 입력 길이와 동일한 다른 시퀀스를 출력한다.
출력 시퀀스는 $$h = (h_{1},...,h_{L})$$이며, L은 너비이다.
② Decoder: Recurrent Character Generator
decoder는 주기적으로 인코더에 의해 생성된 시퀀스를 조건으로 하는 문자들의 순서를 만들어낸다.
attention structure를 함께하는 recurrent neural network이다.
반복하는 부분에 cell로써 GRU를 적용한다.
생성은 T-step 프로세스이다. step t에서 decoder는 attention process를 통해서 attention weight의 벡터를 연산하며 다음과 같이 묘사할 수 있다. $$\alpha_{t} = Attend(s_{t-1}, \alpha_{t-1}, h)$$
s는 마지막 GRU cell의 상태 변수이다.
t=1일때, s와 알파는 제로벡터이다.
그리고 gt(10)은 h의 벡터를 선형적으로 조합하여 연산된다.
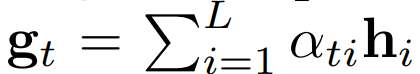 |
(10) |
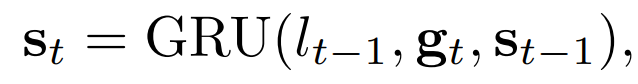 |
(11) |
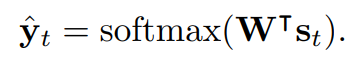 |
(12) |
αt가 1이 되는 음이 아닌 값이기 때문에, 디코더가 초점을 맞추는 위치를 효과적으로 제어한다.
st−1은 GRU의 반복 과정을 통해 업데이트 된다(11).
lt−1은 학습중 (t-1)번째의 ground-truth 라벨이고,
$$\widehat{l}_{t-1}$$는 테스트중에는 이전스텝으로 예측되는 라벨이다.
라벨의 공간의 확률분포는 (12)와 같이 연산된다.
$$\widehat{l}_{t}$$는 확률이 가장 높은 클래스를 선택하여 예측된다.
라벨 공간에는 모든 영문 영숫자와 생성 프로세스를 종료하는 특수 EOS(End-of-sequence) 토큰이 포함된다.
SRN은 입력 시퀀스를 다른 시퀀스에 직접 매핑한다.
입력 및 출력 시퀀스는 모두 임의 길이를 가질 수 있다.
단어 이미지와 관련 텍스트만 사용하여 학습할 수 있다.
3. Model Training
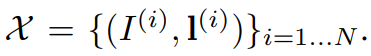 |
(13) |
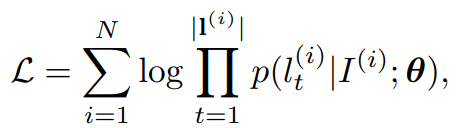 |
(14) |
학습 집합은 (13)과 같이 표기한다.
모델을 학습하기 위해서 (13)에 대한 음의 로그가능도를 최소화한다(14).
(14)의 p는 (12)에 의해 연산되고, θ는 STN와 SRN의 파라미터이다.
최적화 알고리즘은 ADADELTA로 수렴속도가 빠르다.
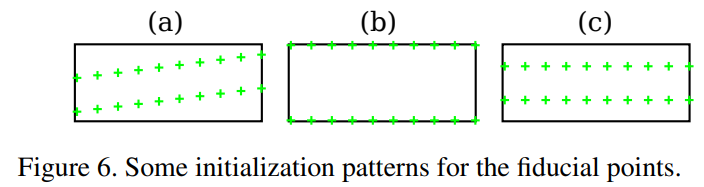
모델 파라미터는 가중치를 0으로 설정하여 출력 fc-layer가 초기화되는 localization network를 제외하고 무작위로 초기화 된다.
초기 bias들은 위그림의 (a)에 표시된 fiducial points 패턴을 산출하는 값으로 설정된다.
경험적으로, 위그림의 (b)와 (c)같이 표기된 패턴들은 상대적으로 저조한 성능을 산출한다.
무작위로 localization network를 초기화 하는것은 학습중 수렴이 실패하는 결과를 낸다.
4. Recognizing With a Lexicon(어휘목록)
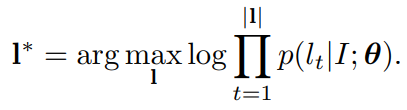 |
(15) |
테스트 이미지가 어휘목록과 연결된 경우, 인식 프로세스는 가장 높은 사후 조건부 확률(15)을 가진 단어를 선택하는 것이다.
그러나 5만개 이상의 단어를 포함하는 Hunspell과 같은 사전에서 (15)와 같은 연산을 하는 것은 사전의 모든 어휘를 반복해야하기 때문에 시간이 많이 걸린다.
대규모 사전에서의 효율적인 근사 검색 체계를 채택하는데
이에 대한 동기는 연산이 같은 접두사를 공유하는 단어들 사이에서 공유될 수 있는 것이다.
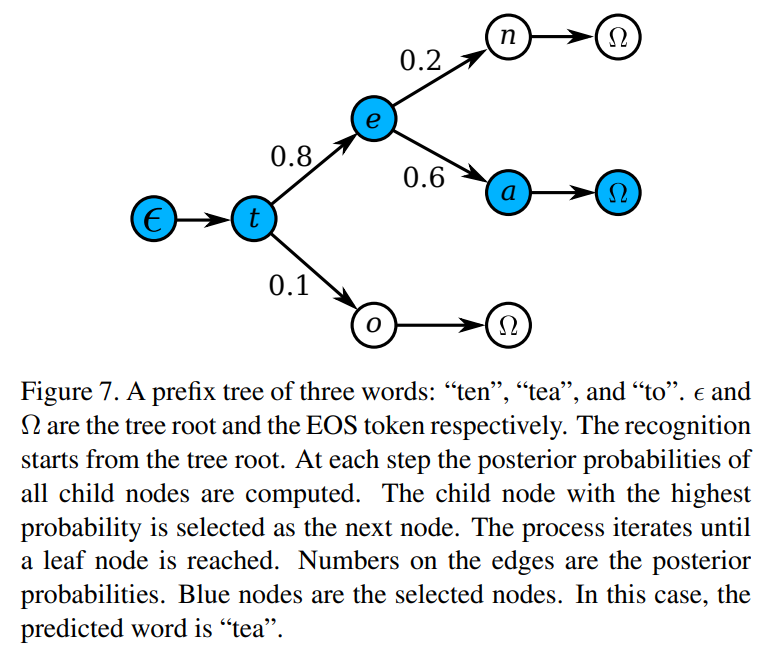
먼저 주어진 어휘의 접두사 트리를 구성한다.
위 그림에 묘사된것과 같이 트리의 각 노드는 문자 라벨이다.
root에서 leaf까지의 경로에 있는 노드들이 단어를 형성한다.
테스트에서 root노드부터 시작하여 모델이 분포 (12)를 출력할 때마다 후방 확률이 가장 높은 자식 노드가 다음으로 이동할 노드로 선택된다.
이 과정은 leaf노드까지 도달할때 까지 반복되고, 단어는 root에서 leaf까지의 경로에서 발견된다.
트리 깊이는 어휘에서 가장 긴 단어의 길이만큼 길기 때문에, 이 검색 프로세스는 정밀한 검색보다 훨씬 적은 계산이 필요하다.
beam search를 통합하여 인식 성능을 더욱 향상시킬 수 있다.
노드들의 목록이 유지 관리되고 상기의 검색 과정은 각 노드들에서 반복된다.
각 단계 후에 목록이 업데이트되어 top-B 누적 로그 우도로 노드를 저장한다. 여기서 B는 beam의 너비이다.
일반적으로 beam의 너비가 클수록 성능은 향상되지만 검색 속도는 감소한다.
Experimental Results
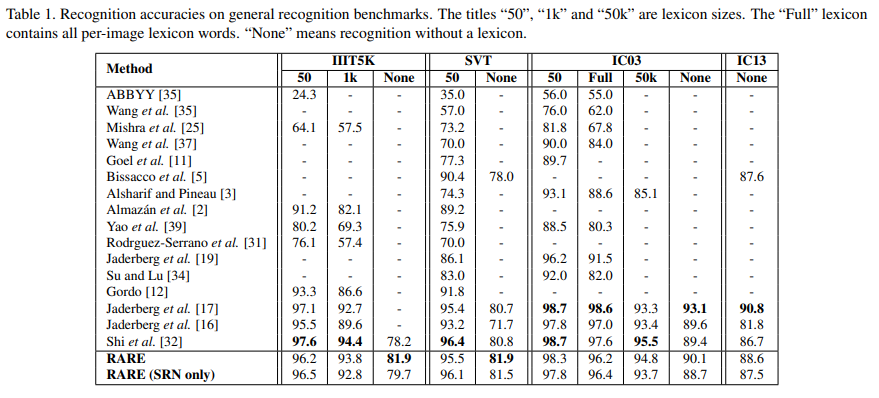

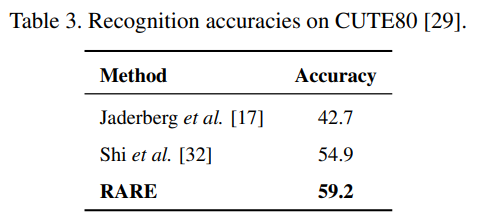
댓글