
논문 : CBAM: Convolutional Block Attention Module
1. Introduction
CNN은 큰 표현력에 기반하여 vision tasks의 성능에 많은 영향을 끼쳤다.
CNN의 성능을 향상시키기 위해서, 최근의 연구들은 주로 중요한 요소인 depth, width, cardinality 를 연구하고 있다.
LeNet부터 ResNet까지 rich representation을 가지며 네트워크는 깊어졌다.
VGGNet은 같은 형태의 블럭을 쌓는 것도 같은 결과를 내는 것을 알려주었다.
같은 맥락으로, ResNet은 깊은 구조를 만들기위해 skip-connection과 함께 같은 형태의 residual blocks를 쌓았다.
GoogleNet은 width가 모델의 성능을 향상시키기 위한 또하나의 중요한 요소임을 알려주었다.
wide residual network 또한 기존의 1001-ResNet 보다 훨씬 뛰어난 성능을 내었다.
Xception과 ResNeXt는 네트워크의 cardinality를 증가시켜는데, 이것이 파라미터의 수를 감소시켜주는 것뿐만아니라 depth와 width보다 더 큰 표현력을 주는 결과를 내었다.
위와 같은 요소들을 바탕으로 Attention 이라는 다른 측면의 구조를 연구하였다.
attention의 중요성은 이전에도 광범위하게 연구되어왔다.
attention은 어디에 집중해야하는지 알려줄뿐만아니라 관심있는부분의 표현력도 향상시켜준다.
본 논문의 목표는 중요한 특징에 집중하고 불필요한 것을 억제하는 attention mechanism으로 표현력을 증가시키는 것이다.
따라서 새로운 네트워크 모듈인 "Convolutional Block Attention Module"을 제안한다.
convolution 연산들이 cross-channel과 spatial 정보를 블렌딩하면서 특징들을 추출해내면서, channel과 spatial 측면의 두 중요한 요소의 크기에 따라 의미있는 특징을 강조하는 모듈을 선택하였다.

본 논문은 위 내용을 이행하기 위해 위 그림과 같은 channel attention과 spatial attention 모듈을 도입하였다.
두 모듈은 각각 '무엇이' '어디에' 있는지에 집중한다.
결과적으로 위 모듈을 적용하는 것이 강조해야하거나 억제해야하는 정보들을 학습하면서 효율적으로 정보들이 흘러가도록 돕는다.
3. Convolutional Block Attention Module
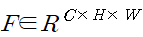 |
(1) |
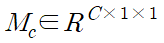 |
(2) |
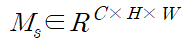 |
(3) |
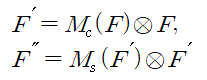 |
(4) |
(1) 같은 중간의 특징을 입력으로 주어졌을 때 CBAM은 순차적으로 (2)와 같은 1차원의 channel attention과 (3)과 같은 2차원의 spatial attention을 나타내며 전체적인 프로세는 (4)와 같이 요약할 수 있으며 ⊗는 element-wise multiplication을 의미한다.
multiplication 연산 중에 channel attention의 정보가 spatial attention으로 흘러가며 F"는 마지막으로 정제된 출력을 의미한다.

Channel Attention
특징들의 채널간의 관계를 이용하면서 channel attention 구조를 만들었다.
특징맵들의 각 채널이 특징검출기라고 여겨지기때문에 channel attention은 입력이미지에서 무엇이 의미있는지 집중한다.
channel attention을 효율적으로 연산하기 위해서 입력 특징맵의 spatial dimension을 짜낸다.
공간적정보를 합치기 위해서, average-pooling이 흔하게 적용되어왔다.
average-pooling을 적용하면 타겟 객체의 크기를 효율적으로 학습하기위해 사용한다고한다.
또한 다른 논문에서는 공간적인 통계를 연산하기 위해 적용한다고 한다.
이러한 연구들을 뒤로하고, max-pooling은 channel-wise attention을 잘 추론하기 위해서 특별한 객체의 특징들에 대해서 또다른 중요한 힌트를 모은다.
따라서 본논문은 average-pooling과 max-pooling을 동시에 사용한다.
두가지 pooling을 사용하면 표현력이 증가했다.
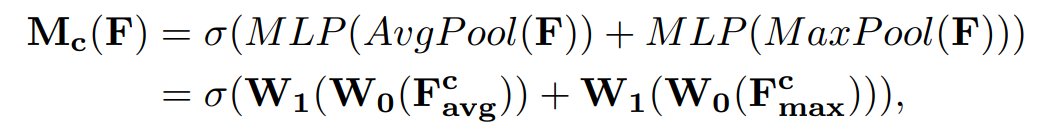
Spatial Attention
본 논문의 spatial attention은 특징들의 공간적인 관계를 활용해서 만들었다.
channel attention과 다른점은 spatial attention은 정보를 담은 부분이 ' 어디' 인지에 집중했는다는 것이다.
spatial attention을 연산하기 위해서, 채널 축을 따라서 average-pooling과 max-pooling을 적용하고 효율적인 feature descriptor를 생성하기위해서 합친다.
채널축을 따라서 pooling 연산들을 적용한것은 정보가 담겨있는 구역을 강조하는 효과를 준다.
그후 convolutional layer를 적용해서 어디를 강조하고 억제할지에 대해 엔코딩하는 역할을 한다.

4. Experiments


'Paper > Object Detection' 카테고리의 다른 글
| Swin Transformer : Hierarchical Vision Transformer using Shifted Windows (1) | 2022.03.10 |
|---|---|
| Augmentation for small object detection (1) | 2021.11.02 |
| YOLO_v4 (1) | 2021.10.27 |
| Scaled-YOLOv4 (1) | 2021.07.13 |
| MDSSD : Multi-scale Deconvolutional Single Shot Detector for Small Object (0) | 2021.04.15 |




댓글