
[Abstract]
- transformer를 자연어처리에서 비전분야에 적용하는 것은 1) visual entity의 크기 큰 변화 2) 텍스트보다 높은 화질 의 차이 때문에 어렵다.
- 이러한 차이를 다루기 위해 Shifted windows로 representation을 계산하는 hierarchical Transformer를 제안한다.
- Shifted windows 방식은 기존 self-attention의 제곱에 비례하는 계산량을 선형 비례하게 줄이면서도 다양한 scale을 처리할 수 있는 접근법이다.
- 이미지 분류, 객체 검출, segmentation과 같이 넓은 분야에 호환될 수 있게 했다.
[Introduction]
컴퓨터 비전은 오랬동안 CNN이 지배적이였다. Alexnet을 시작으로 이미지분류에서의 큰 성능을 보여주면서 CNN 구조는 더 큰 스케일, 더 광범위한 연결들과 더 정교한 형태의 컨볼루션으로 진화하였다. CNN들이 다양한 비전 task의 backbone으로 역할을 하면서 이러한 구조적인 진화는 전체적인 분야로 옮겨가며 성능향상을 이끌었다.
반면에, 자연어 처리(NLP)에서의 네트워크 구조의 진화는 transformer를 통해 발전해왔다. sequence modeling과 변환작업을 위해 설계된 Transformer는 데이터의 장거리 의존성을 모델링하는데 attention을 사용하는 것으로 유명하다. 언어분야에서의 엄청난 성공은 컴퓨터 비전에 적용하는 방향으로 연구하게 했으며 이미지 분류, joint vision-language과 같은 task에서 촉망되는 결과를 입증하였다.
이 논문에서는 컴퓨터 비전에서 다목적의 backbone으로써 수행되는 Transformer의 적용을 넓히는 방법을 찾고자한다. 언어분야에서 비전분야로 높은 성능을 옮길수 있는 중요한 문제는 두 양상의 차이로 설명할 수 있다.
1) scale : language Transformer 처리의 기본 요소 역할을 하는 단어 토큰과는 달리, 시각적 요소는 크기가 다양한다. 현존하는 transformer 기반의 모델들은 토큰들이 모두 고정된 크기이며, 이것은 vision task에 적합하지 않은 특성이다.
2) 텍스트보다 훨씬 높은 해상도 : 픽셀 수준에서 고밀도 예측(dense predictions)이 필요한 semantic segmentation과 같은 vision task에서는 Self-attention의 계산 복잡성이 이미지 크기에 따라 제곱으로 증가하기 때문에 고해상도 이미지에서는 Transformer의 사용이 어렵다.
이러한 문제들을 극복하기 위해 계층적 피쳐 맵을 구성하고 이미지 크기에 대한 선형 계산 복잡성을 가지는 다목적의 Transformer backbone, Swin Transformer를 제안한다. 아래의 그림(a)와 같이 작은 크기의 패치(patch)에서 시작해 점차 더 모델이 깊어질수록 인점한 패치들을 병합하며 계층적인 특징표현(hierarchical representation)을 구성할 수 있게 된다. Swin Transformer의 이러한 특성으로 인해 FPN과 U-net같은 고밀도 예측을 위한 advanced task에도 영향력을 줄 수 있다. 선형 계산 복잡성은 이미지를 분할하는 겹치지 않는 window 내에서 로컬로 self-attention을 계산함으로써 얻어진다. 각 window에서의 패치의 수는 고정된다. 따라서 복잡성은 이미지 크기에 비례한다. 이전의 Transformer 기반의 구조들이 단일 해상도의 특징맵을 생성하고 이미지 크기에 대해 제곱으로 증가하는 복잡성을 가졌던 것에 비해 이러한 장점들이 Swin Transformer가 다양한 vision task들의 다목적 backbone으로써 적합하게 한다.

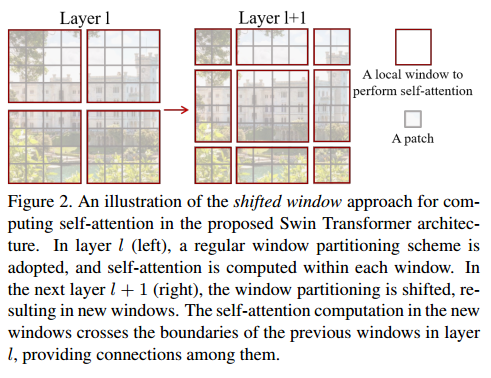
Swin Transformer의 중요한 설계요소는 위 그림과 같은 연이은 self-attention 레이어들 사이의 shift windows이다. shift windows는 이전의 윈도우들과 연결해주며 모델링 성능을 크게 향상시킨다. self-attention 계산을 수행할 때, sliding window 방식에서는 각각 다른 query pixel에 대해 다른 key sets에 대해 계산을 수행해야 해서 일반적인 하드웨어에서 low latency 문제를 경험하게 된다.
이와 달리 shifted window 방식은 window 내의 모든 query patch는 같은 key set을 공유하기 때문에 하드웨어 상에서 memory access 면에서 latency가 더 적기 때문이다.
[Method]
-Overall Architecture-

맨 앞에 Patch partition 과정이 있다. 여기서는 먼저 ViT와 같은 patch 분리 모듈을 통해 입력 RGB 이미지를 겹치지 않는 patch들로 나눈다. 각 patch들은 하나의 token으로 여겨지고 그거의 feature는 raw pixel RGB 값을 이어붙인 것이다. 이 논문에서는 각 patch의 크기는 4×4이며, 따라서 feature의 크기는 4×4×3=48이다. linear embedding layer는 임의의 크기(C)에 투영하기 위해 raw-valued feature에 적용된다. 위 그림의 여러개의 Swim Transformer Block들은 patch token들에 적용된다. Transformer block들은 token 수를 유지한다(H/4 × W/4). linear embedding과 함께 있는 것이 Stage 1이다.
계층적인 특징표현을 생산하기 위해 네트워크가 깊어질수록 token의 수는 patch merging layer들을 통해 감소된다. 첫 patch merging layer는 인접한 (2×2)=4개의 patch들끼리 결합하고 4C의 크기로 합쳐진 feature들을 linear layer에 적용하여 2C로 맞춰진다. 따라서 patch merging을 통과하면 해상도는 2×2배 줄고 채널은 2배로 늘어난다. 이후 feature transformation에는 해상도가 (H/8 × W/8)로 유지되며 Swim Transformer Block들이 적용된다. 이 patch merging과 feature transformation의 블록이 stage2이다. 이 절차는 stage3, 4로 두 번 반복되며 각 (H/16 × W/16), (H/32 × W/32)의 출력을 낸다. 이 stage들은 일반적인 컨볼루션 네트워크와 동일한 feature map 해상도로 연대적으로 계층적인 특징표현을 생산한다. 결과적으로 제안하는 구조는 알맞게 존재하는 다양한 vision task들을 위한 backbone 네트워크를 대체할 수 있다.
* Self-Attention은 입력한 문장 내의 각 단어를 처리해 나가면서, 문장 내의 다른 위치에 있는 단어들을 보고 힌트를 받아 현재 타겟 위치의 단어를 더 잘 인코딩할 수 있게 하는 과정
Swin Transformer block
Swin Transformer block은 Transformer block안의 다른 layer들은 유지하며 표준의 MSA(multi-head self-attention) 모듈을 shifted windows를 기반으로 하는 모듈로 대체하여 만들어진다. 그림3의 (b)에 묘사된 것과 같이, Swin Transformer block은 shifted windows를 기반으로 하는 MSA 모듈과 이어지는 2-layer의 MLP로 구성되어 있다. LayerNorm(LN) layer는 각 MSA와 MLP layer 사이에 적용되며 각 모듈 뒤에 residual connection이 적용된다.
-Shifted Window based Self-Attention-
표준의 Transformer 구조와 이미지 분류에 이를 적용한 것 둘다 하나의 token과 다른 모든 token들 사이의 관계를 연산하는 global self-attention을 수행한다. 이 방법은 계산 복잡도가 입력 이미지 해상도에 대해서 제곱으로 증가하게 되고 dense한 예측이나 높은 해상도의 이미지에 적용하기에는 어려움이 있다.
Self-attention in non-overlapped windows
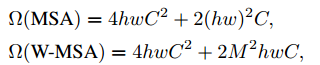
효과적인 모델링을 위해서 local windows에서 self-attention을 연사하는 것을 제안한다. windows는 겹치지 않는 방식으로 고르게 나열된다. 각 window가 MxM개의 patch를 포함한다고 가정할 때, global MSA 모듈과 window가 기반인 것의 연산 복잡성은 위의 식과 같이 나타낼 수 있다. 기존 MSA 모듈에서 패치 내부의 해상도 hw에 제곱으로 증가하는 반면 W-MSA 모듈에서는 패치 내부에서만 계산이 발생하기 때문에 한 window 내부의 패치의 수 M×M에 따라 증가한다. global self-attention 연산은 일반적으로 큰 hw에 대해서는 비용이 많이 드는데 window기반의 self-attention은 측정할 수 있는 정도이다.
Shifted window partitioning in successive blocks
window기반의 self-attention 모듈은 window들 간의 연결성이 부족하고 이는 모델링 성능을 제한한다. 겹치지 않는 방식의 windows의 효율적인 연산을 유지하면서 cross-window connections을 도입하기 위해서 연속되는 Swin Transformer block에서 두 개의 분할되는 구성에서 사용되는 shifted window partitioning 접근법을 제안한다.
위 그림에 묘사된 것과 같이, 첫 번째 모듈은 왼쪽 상단에서 시작하는 일반적인 window partitioning 전략을 사용한다. 그리고 8 × 8 feature map은 고르게 4×4 (M = 4)크기의 2×2 windows로 나뉘어진다. 그다음 모듈은 이전 layer의 규칙적으로 분할된 windows로부터 (M/2 ,M/2) pixel씩 움직여 위치하는 windowing configuration을 쓴다.
shifted window partitioning 접근법과 함께 연속적인 Swin Transformer blocks는 아래의 식과 같이 연산된다.

shifted window partitioning 접근법은 이전 layer에서의 이웃하는 겹치지 않는 window들 사이의 연결성을 도입하며 image classification, object detection, and semantic segmentation에서 효과적인 것을 발견했다.
Efficient batch computation for shifted configuration
shifted window partitioning 문제는 [h/M] x [w/M]에서 ([h/M]+1) x ([w/M]+1)로 변형된 양상과 같이 더 많은 window들에 대한 결과와 몇몇의 window들이 MxM보다 더 작아진다는 것이다.

이를 해결하기 위해 위 그림과 같이 왼쪽 상단 패치부터 옮기는 Cyclic-shifting 방법을 제안한다. A,B,C구역을 mask를 씌워서 self-attention을 하지 못하도록 한다. 그 이유는 원래 ABC 구역은 좌상단에 있었던 것들이기 때문에 반대편에 와서 self-attention을 하는 것은 의미가 별로 없기 때문이다. 마스크 연산을 한 후에는 다시 원래 값으로 되돌린다. padding을 사용해 마스킹을 대신할 수 있지만 저자들은 이 방법은 computation cost를 증가시키기 때문에 택하지 않았다고 한다.
Relative position bias
Self-attention을 계산하는 과정에서 Relative position bias 를 더함으로써 위치적 정보를 모델링할 수 있도록 했다. 이 bias는 window 내부에서의 위치를 모델링하는 것이다.
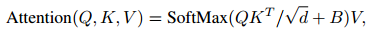
위 식을 보면 기존 ViT에서 softmax를 취하기 전에 B를 더하는 것을 볼 수 있는데 이것이 바로 Relative position bias이다. 기존에 position embedding은 절대좌표를 그냥 더해주었는데 본 논문에서는 상대좌표를 더해주는 것이 더 좋은 방법이라고 제시한다.
Architecture Variants
'Paper > Object Detection' 카테고리의 다른 글
| Attention Is All You Need (3) | 2022.03.14 |
|---|---|
| Augmentation for small object detection (1) | 2021.11.02 |
| CBAM (0) | 2021.10.28 |
| YOLO_v4 (1) | 2021.10.27 |
| Scaled-YOLOv4 (1) | 2021.07.13 |




댓글