
[Introduction]
RNN, LSTM, Gated recurrent network는 언어 모델링 및 기계 번역과 같은 순차 모델링 및 변환 문제에서의 최신의 접근법으로 자리잡고있었다. 그 이후로 반복 언어 모델과 인코더-디코더 아키텍처의 경계를 확장하기 위한 수많은 노력이 계속되었다. 반복 모델은 전형적으로 입력과 출력 시퀀스의 기호 위치를 따라 계수를 계산한다. 계산 단계에서 위치를 적절히 맞추기 위해 이전 상태 치 t의 함수인 은닉상태 ht를 생성한다. 이 본질적인 sequenial 특성은 학습에서의 병렬화를 불가능하게 한다. 메모리 제한으로 인해 sequence가 길어지면 병렬화가 불가능하다. 최근에는 인수분해 트릭들과 조건적인 계산으로 연산효율성과 모델 성능을 향상시켰다. 하지만 근본적인 sequential computation의 제한은 아직 남아있다.
Attention mechanism들은 입력 또는 출력 시퀀스의 거리에 관계 없이 종속성 모델링 허용하면서 다양한 task에서의 모델 변환과 강력한 sequence modeling 부분에서 필수적인 요소가 되었다. 그러나 몇가지 경우를 제외하고 모든 경우에서 이러한 attention mechanism들은 recurrent network과 함께 결합으로 사용된다.
이 논문에서는 recurrent를 피하고 대신 입력과 출력 사이의 global dependency를 도출하기 위해 attention mechanism에 전적으로 의존하는 Transformer 모델을 제안한다. Transformer는 훨씬 더 많은 병렬화를 가능하게 하고 8개의 P100 GPU에서 12시간 동안 학습하며 번역에서의 새로운 sota에 도달할수 있었다.
[Model Architecture]
대부분의 경쟁력있는 sequence 변환 모델들은 encoder-decoder 구조를 가지고 있다. encoder는 symbol representations의 입력 sequence(x1,...,xn)를 연속적인 representation의 sequence(z = z1, ..., zn)에 매핑시킨다. z가 주어지면 decoder는 한번에 한 원소씩 출력 sequence 를 생성한다. 각 단계는 자동회귀이며 다음 단계의 symbol을 생성할 때 이전 단계에서 생성된 symbol을 추가 입력으로 받는다.
Transformer는 encoder, decoder 모두 쌓은 self-attention, point-wise, fully connected layers 구조를 가진다.
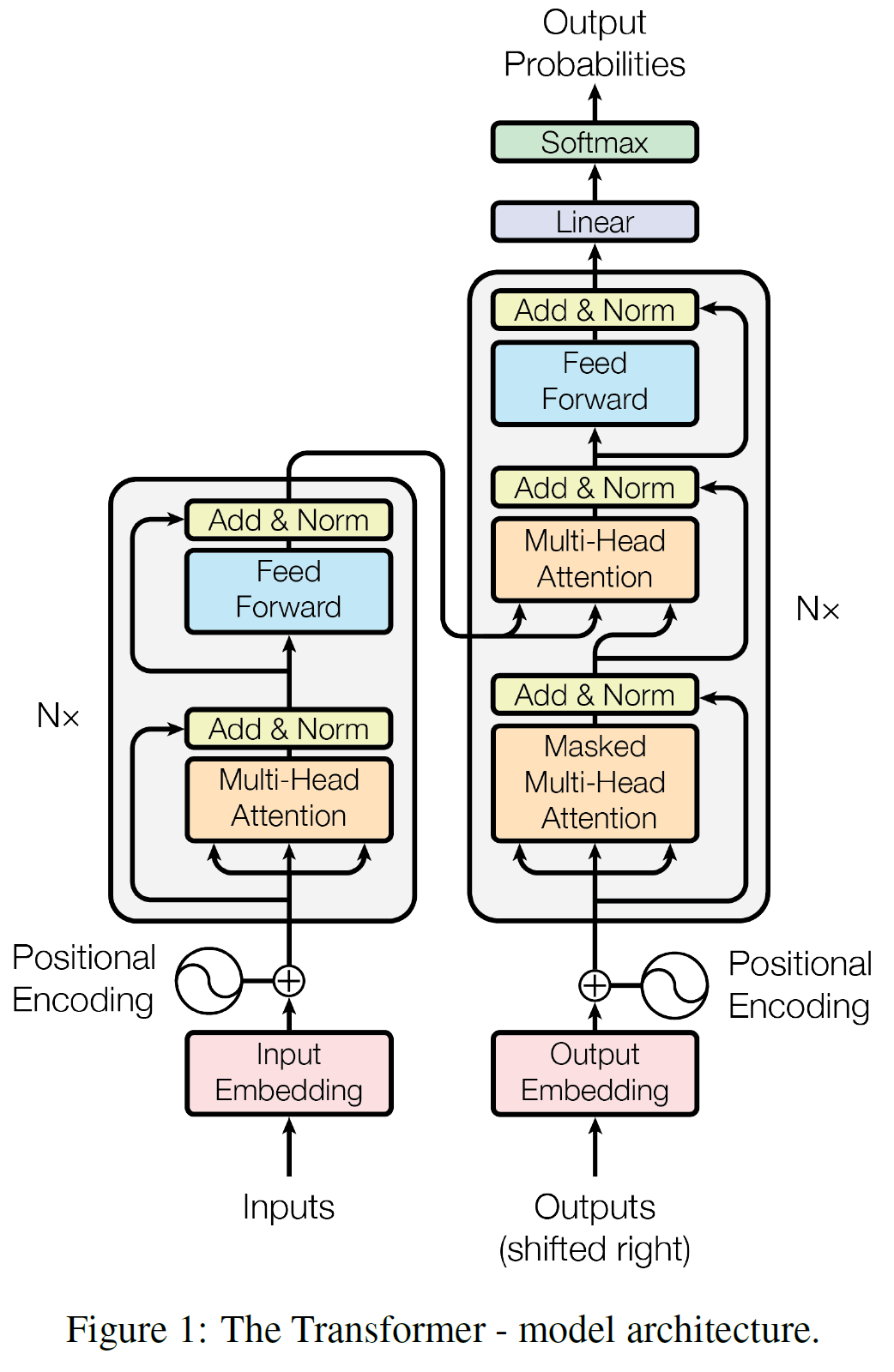
- Encoder and Decoder Stacks -
Encoder : encoder는 동일한 레이어 N=6으로 구성되어있다. 각 레이어는 두개의 sub-layer를 가진다. 첫번째 레이어는 multi-head self attention mechanism이고 두번째 레이어는 간단한 position wise fully connected feed-forward network이다. 각 sub-layer는 residual connection을 하고 있으며 layer normalization이 뒤따른다. 각 sub-layer의 출력은 LayerNorm(x + Sublayer(x))이고 Sublayer(x)는 sub-layer 자체에 실행되는 함수이다. 이 residual connection을 용이하게 하기위해서 모든 sub-layer들은 512차원의 크기를 갖는다.
Decoder : decoder 또한 동일한 레이어 N=6으로 구성되어있다. decoder는 2개의 sub-layer 뿐만 아니라 encoder stack의 출력값에 multi-head attention을 수행하는 3번째 sub-layer도 포함한다. encoder와 비슷하게 각 sub-layer들에 residual connection을 적용했으며 layer normalization을 적용했다. 디코더가 출력을 생성할 때 다음 출력에서 정보를 얻는 것을 방지하기 위해self-attention을 수정하였다. 출력 임베딩이 한 위치만큼 오프셋되는 요소를 결합하는 이 masking 기법은 i 위치에대한 예측이 i 보다 전에 존재하는 알수있는 출력에만 의존할수 있게 한다.
- Attention -
attention 함수는 하나의 쿼리와 키-값을 출력으로 매핑하는 것으로 묘사할 수 있다. 출력은 value의 가중 합으로써 연산되며 여기서 각 value에 할당된 가중치는 쿼리와 해당 키의 호환성 함수에 의해 연산된다.
Scaled Dot-Product Attention

특정한 attention을 "Scaled Dot-Product Attention"이라고 칭한다. 입력은 queries와 dk 크기의 keys과 dv 크기의 values로 구성된다. 아래의 식과 같이 연산하다.
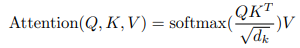
가장흔하게 사용되는 attention 함수는 additive attention과 dot-product attention이다. 최적화된 매트릭스 곱셈 코드를 사용하여 구현할 수 있기 때문에 dot-product attention이 훨씬 빠르고 공간 효율성도 뛰어나다.
" 1/sqrt(dk)로 Scaling하는 이유는, QK^T 연산을 하게 되면 행렬 크기가 커지게 되면서 벡터가 커지게 된다. 따라서 벡터를 구성하는 숫자의 개수가 여러개가 되기 때문에 Softmax를 적용하면 거의 대부분의 숫자들이 0에 가깝게 된다.(Softmax는 확률을 나타내는 함수이기 때문에 각 행렬의 위치들이 얼만큼의 확률을 나타내는지를 보이기 때문에 행렬이 클수록 모든 데이터들이 0에 가까워질 수 밖에 없다.) 따라서 각 숫자들의 값들의 차이를 극단적으로 나누기 위해 (대부분의 숫자들이 0에 가까운 것을 막기 위해)1/sqrt(dk)로 Scaling하게 된다. "
https://welcome-to-dewy-world.tistory.com/108 참조
Multi-Head Attention
동일한 d 크기의 keys, values, query와 함께 single attetion 함수를 적용하는 대신, 각 다른 크기의 차원으로 h번 학습하는 것이 더 효과적이다. keys, values, query에 병렬적으로 attention 함수를 적용하며 dv 크기의 출력값을 낸다.
multi-head attention은 모델이 서로 다른 위치에서 서로 다른 표현의 정보를 공동으로 확인할 수 있게한다.

Applications of Attention in our Model
transformer는 세가지 다른 방식으로 multi-head attention을 사용한다.
* "encoder-decoder attention"레이어에서는 queries가 이전의 decoder layer에서 오며, memory key와 value는 encoder의 출력으로 부터 온다. 이는 decoder에서의 모든 위치가 입력 시퀀스에서의 모든 위치들을 고려할 수 있게 한다.
* encoder는 self-attention layer를 포함한다. 여기서의 모든 query, key, value는 모두 같은 곳에서 오는데, encoder의 이전 layer의 출력이다. encoder에서의 각 위치는 이전 layer에서의 몸든 위치들을 고려할 수 있다.
* 비슷하게, decoder에서의 self-attention은 decoder안의 각 위치들이 모든 위치들을 고려할 수 있다. auto-regressive(자기 자신을 입력으로 하여 자기 자신을 예측하는) 특성을 보존하기 위해 decoder에서 왼쪽으로 향하는 정보의 흐름을 막아야 한다(미래의 단어 볼 수 없게). 이를 위해 매우 작은 수를 부여하여 softmax 결과 0에 수렴하도록 하여 masking을 수행한다. 잘못된 연결에 해당하는 소프트맥스 입력의 모든 값을 마스킹(-무한)으로 설정)하여 Scaled Dot-Product Attention의 내부에서 이를 구현한다.
Position-wise Feed-Forward Networks
attention의 sub-layer에 추가적으로 encoder와 decoder 내의 각 layer들은 fully connected feed-forward network를 포함하며 각 위치에 개별적으로 동일하게 적용된다. 이것은 사이에 ReLU 활성화 함수가 있는 ㅊ두개의 linear transformation으로 구성된다.

linear transformation들이 다른 위치들에 걸처 같은 반면에, layer 마다 다른 파라미터를 사용한다. 이것을 설명할 수 있는 다른 방법은 커널 크기가 1인 두개의 컨볼루션을 사용하는 것이다. 입출력의 차원의 크기는 512이고, inner-layer 2048 이다.
Embeddings and Softmax
다른 시퀀스 변형 모델과 비슷하게, 입출력 토큰을 d 크기의 벡터로 변화하기 위해 embeddings를 사용한다. 또한 decoder의 출력을 예측된 next-token 확률로 변형시키기 위해 학습된 선형 변형 형과 softmax를 사용한다. 본 논문이 제안하는 모델은 두개의 embedding layer들과 pre-softmax linear transformation 사이에서 같은 가중치 행렬을 공유한다.
Positional Encoding
본 논문의 모델이 rnn, cnn을 포함하지 않기 때문에 모델이 시퀀스의 순서를 사용하기 위해서 시퀀스 내의 상대적이거나 절대적인 토큰의 위치에 관한 몇가지 정보를 주입해야한다. 맨 밑 encoder와 decoder에서의 input embeddings에 positional encodings를 더한다. positional encodings는 embeddings와 같은 차원의 크기를 같기 때문에 더해질 수 있다. 여기에는 sin, cos 함수를 사용한다.
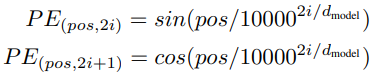
위 식에서 pos는 position이며 i는 크기이다. 즉, 각 positional encoding의 크기는 sinusoid(사인곡선)과 일치한다. geometric progression wavelengths 은 2π에서 10000까지이다. PE_pos+k가 PE_pos의 선형 함수로 표현될 수 있기에 모델이 상대적인 위치를 쉽게 학습할 수 있을 것이라 가정했기 때문에 이 함수를 사용한다. 학습가능한 positional embedding을 사용해 봤지만 동일한 성능을 보이는 것을 확인할 수 있었고, 더 긴 시퀀스에서도 추론이 가능한 사인파 버전을 사용한다.
[Why Self-Attention]
self attention과 rnn, cnn과의 비교를 수행한다.
첫번째는 layer마다의 총 연산 복잡성이다. 두번째는 필요한 최소의 sequential operation의 수로 측정되는 병렬로 연산될수 있는 양이다. 세번째는 Network에서 long-range dependencies(장거리 의존성) 사이 path length. long-range dependencies의 학습은 번역 업무에서 핵심 task이다. 이러한 dependencies을 학습하는 능력에 영향을 미치는 한 가지 핵심 요소는 전달해야 하는 forward 및 backward signal의 길이다. Input의 위치와 output의 위치의 길이가 짧을수록 dependencies 학습은 더욱 쉬워진다. 그래서 서로 다른 layer types로 구성된 네트워크에서 input과 output 위치 사이 길이가 maximum 길이를 비교한다.
https://silhyeonha-git.tistory.com/16 참조
'Paper > Object Detection' 카테고리의 다른 글
| Swin Transformer : Hierarchical Vision Transformer using Shifted Windows (1) | 2022.03.10 |
|---|---|
| Augmentation for small object detection (1) | 2021.11.02 |
| CBAM (0) | 2021.10.28 |
| YOLO_v4 (1) | 2021.10.27 |
| Scaled-YOLOv4 (1) | 2021.07.13 |




댓글